导语
我们编写程序 write 数据到文件中时,其实数据不会立马写入磁盘,而是会经过层层缓存。每层缓存都有自己的刷新时机,每层缓存都刷新后才会写入磁盘。这些缓存的存在是为了加速读写操作,因为如果每次读写都对应真实磁盘操作,那么读写的效率会大大降低。带来的坏处是如果期间发生掉电或者别的故障,还未写入磁盘的数据就丢失了。对于数据安全敏感的应用,比如数据库,比如交易程序,这是无法忍受的。所以操作系统提供了保证文件落盘的机制。我们来看下这些机制的原理和使用。
I/O缓冲区机制
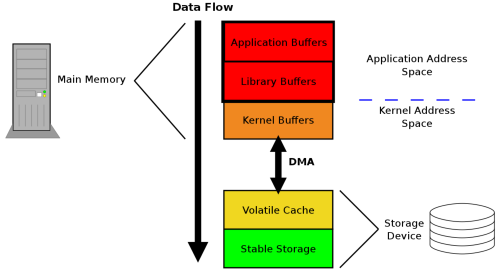
图片来自:Ensuring data reaches disk [LWN.net]
上图说明了操作系统到磁盘的数据流,以及经过的缓冲区。首先数据会先存在于应用的内存空间,如果调用库函数写入,库函数可能还会把数据缓存在库函数所维护的缓冲区空间中,比如 C 标准库 stdio 提供的方法就会进行缓存,目的是为了减少系统调用的次数。这两个缓存都是在用户空间中的。库函数缓存刷新时,会调用 write 系统调用写入内核空间,内核同样维护了一个页缓存(page cache),操作系统会在合适的时间把脏页的数据写入磁盘。即使是写入磁盘了,磁盘也可能维护了一个缓存,在这个时候掉电依然会丢失数据的,只有写入了磁盘的持久存储物理介质上,数据才是真正的落盘了,是安全的。我们接下来就是要研究如何做到这一步。
用户空间缓冲区
用户空间的缓存分为应用程序本身维护的缓冲区与库维护的缓冲区。
应用本身维护的缓冲区需要开发者自己刷新,调用库函数写入到库函数的缓冲区中。如果应用程序不依赖任何库函数,而是直接使用系统调用,那么则是把数据写入系统的缓冲区去。
库函数一般都会维护缓冲区,目的是简化应用程序的编写,应用程序就不需要编写维护缓冲区的代码,同时性能也得到了提高,因为缓冲区大大减少了系统调用的次数,而系统调用是非常耗时的,系统调用涉及到用户态到内核态的切换,这个切换需要很多的步骤与校验,较为耗时。
比如 C 标准库 stdio 就维护着一个缓冲区,对应这个缓冲区,C 标准库提供了 fflush 方法强制把缓冲区数据写入操作系统。
Java 的 OutputStream 接口提供了一个 flush 方法,具体的作用要看实现类的具体实现。BufferedOutputStream#flush 就会把自己维护的缓冲区数据写入下一层的 OutputStream。如果是 new BufferedOutputStream(new FileOutputStream("/")) 这样的模式,则调用 BufferedOutputStream#flush 会将数据写入操作系统。
内核缓冲区
应用程序直接或者通过库函数间接的使用系统调用 write 将数据写入操作系统缓冲区。
UNIX系统在内核中设有高速缓存或页面高速缓存。目的是为了减少磁盘读写次数。
用户写入系统的数据先写入系统缓冲区,系统缓冲区写满后,将其排入 输出队列,然后得到队首时,才进行实际的IO操作。这种输出方式被称为 延迟写。
UNIX系统提供了三个系统调用来执行刷新内核缓冲区:sync,fsync,fdatasync。
4.1. sync
void sync(void)
sync函数只是将所有修改过的块缓冲区排入输出队列就返回,并不等待实际的写磁盘操作返回。
操作系统的update系统守护进程会周期地调用sync函数,来保证系统中的数据能定期落盘。
根据sync(2) - Linux manual page的描述,Linux对sync的实现与POSIX规范不太一样,POSIX规范中,sync可能在文件真正落盘前就返回,而Linux的实现则是文件真正落盘后才会返回。所以Linux中,sync与fsync的效果是一样的!但是1.3.20之前的Linux存在BUG,导致sync并不会在真正落盘后返回。
4.2. fsync
void fsync(int filedes)
fsync对指定的文件起作用,它传输内核缓冲区中这个文件的数据到存储设备中,并阻塞直到存储设备响应说数据已经保存好了。
fsync对文件数据与文件元数据都有效。文件的元数据可以理解为文件的属性数据,比如文件的更新时间,访问时间,长度等。
4.3. fdatasync
void fdatasync(int filedes)
fdatasync和fsync类似,两者的区别是,fdatasync不一定需要刷新文件的元数据部分到存储设备。
是否需要刷新文件的元数据,是要看元数据的变化部分是否对之后的读取有影响,比如文件元数据的访问时间st_atime和修改时间st_mtime变化了,fdatasync不会去刷新元数据数据到存储设备,因为即使这个数据丢失了不一致了,也不影响故障恢复后的文件读取。但是如果文件的长度st_size变化了,那么就需要刷新元数据数据到存储设备。
所以如果你每次都更新文件长度,那么调用fsync和fdatasync的效果是一样的。
但是如果更新能做到不修改文件长度,那么 fdatasync 能比fsync少了一次磁盘写入,这个是非常大的速度提升。
4.4. O_SYNC 和 O_DSYNC
除了上面三个系统调用,open 系统调用在打开文件时,可以设置和同步相关的标志位:O_SYNC 和 O_DSYNC。
设置 O_SYNC 的效果相当于是每次 write 后自动调用 fsync。
设置 O_DSYNC 的效果相当于是每次 write 后自动调用 fdatasync。
4.5. 关于新建文件
在一个文件上调用 fsync / fdatasync 只能保证文件本身的数据落盘,但是对于文件系统来说,目录中也保存着文件信息,fsync / fdatasync 的调用并不会保证这部分的数据落盘。如果此时发生掉电,这个文件就无法被找到了。
所以对于新建文件来说,还需要在父目录上调用 fsync。
4.6. 关于覆盖现有文件
覆盖现有文件时,如果发生掉电,新的数据是不会写入成功,但是可能会污染现有的数据,导致现有数据丢失。
所以最佳实践是新建一个临时文件,写入成功后,再替换原有文件。具体步骤:
- 新建一个临时文件
- 向临时文件写入数据
- 对临时文件调用
fsync,保证数据落盘。期间发生掉电对现有文件无影响。 - 重命名临时文件为目标文件名
- 对父目录调用
fsync
存储设备缓冲区
存储设备为了提高性能,也会加入缓存。高级的存储设备能提供非易失性的缓存,比如有掉电保护的缓存。但是无法对所有设备做出这种保证,所以如果数据只是写入了存储设备的缓存的话,遇到掉电等故障,依然会导致数据丢失。
对于保证数据能保存到存储设备的持久化存储介质上,而不管设备本身是否有易失性缓存,操作系统提供了write barriers这个机制。
开启了write barriers的文件系统,能保证调用fsync/fdatasync数据持久化保存,无论是否发生了掉电等其他故障,但是会导致性能下降。
许多文件系统提供了配置write barriers的功能。比如ext3, ext4, xfs 和 btrfs。mount参数-o barrier表示开启写屏障,调用fsync/fdatasync能保证刷新存储设备的缓存到持久化介质上。-o nobarrier则表示关闭写屏障,调用fsync/fdatasync无法保证数据落盘。
Linux默认开启写屏障,所以默认情况下,我们调用fsync/fdatasync,就可以认为是文件真正的可靠落盘了。
对于这个层面的数据安全保证来说,应用程序是不需要去考虑的,因为如果这台机器的硬盘被挂载为没有开启写屏障,那么可以认为这个管理员知道这个风险,他选择了更高的性能,而不是更高的安全性。
总结
- 文件数据从应用程序写入磁盘,需要经过多个缓冲区:应用本身的缓冲区,库的缓冲区,操作系统缓冲区,磁盘缓冲区
- 如果文件数据只是写入缓冲区,而还未写入硬盘的持久化存储设备上,那么断电等故障会导致数据丢失
- 库层面刷新缓冲区:C标准库的
fflush,JDK的OutputStream#flush - 操作系统层面刷新缓冲区:
fsync可以刷新文件数据+元数据缓冲区fdatasync可以刷新文件数据,在不影响读取的情况下,可以不刷新文件元数据,性能更好一些open系统调用的O_SYNC标志位可以在每次write后自动调用fsyncopen系统调用的O_DSYNC标志位可以在每次write后自动调用fdatasync- 存储设备层面刷新缓冲区:文件系统支持开启/关闭写屏障
write barriers,如果开启写屏障,则fsync/fdatasync可以保证文件写入磁盘的持久化设备中,如果关闭写屏障,则fsync/fdatasync只能保证文件写入磁盘,此时文件可能存在于磁盘的缓存中
参考资料
- 《UNIX环境高级编程》
- Ensuring data reaches disk
- linux 同步IO: sync、fsync与fdatasync - CSDN博客
- sync(2) - Linux manual page
- fsync(2) - Linux manual page
- sync/fsync/fdatasync的简单比较 - CSDN博客
- Everything You Always Wanted To Know About fsync() - xavier roche’s homework
- Linux OS: Write Barriers - 德哥@Digoal的日志 - 网易博客
- Linux Barrier I/O 实现分析与barrier内存屏蔽分析总结 - 综合编程类其他综合 - 红黑联盟
- Chapter 16. Write Barriers
- Barriers and journaling filesystems [LWN.net]